| Laboratorul 1 | Sisteme de înregistrare a datelor pe suport magnetic |
-continuare-
�n cadrul nivelului RAID 5, data este �mpartita de-a lungul tuturor discurilor din matrice, folosind felii largi, cu c�te o felie pe "linie", contin�nd datele de paritate. Alocarea acestei felii de paritate este rotita printre toate discurile din matrice astfel �nc�t feliile succesive de paritate sunt �ntotdeauna scrise pe un disc diferit. �n eventualitatea "caderii" unuia din ele (drive failure), continutul fiecarei felii lipsa poate fi reconstruit din data de paritate pentru acea "linie", astfel nepierz�ndu-se nici un fel de date. Caderea �ntregii matrici reclama caderea simultana a doua drivere - un eveniment foarte improbabil.
Felierea discului cu paritate rotativa ( Disk striping with rotating parity)
A memora datele de paritate �nseamna ca �n orice moment �n care o data este scrisa pe un disc din matrice, paritatea trebuie sa fie reactualizata. Daca datele de paritate au fost mereu scrise pe un acelasi disc, acest disc va deveni o problema (a bottle-neck) pentru celelalte discuri, cu un efect negativ care va reduce performanta sistemului la scriere. Prin rotirea discului care memoreaza felia scrisa, aceasta �ncurcatura este �nlaturata si acest efect negativ este redus. Mai mult, partajarea datelor si a paritatii de-a lungul discurilor permite aceleasi performante la citire ca �n cazul �n care nu exista un disc de paritate dedicat.
�n figura urmatoare sunt ilustrate operatiile de scriere/citire pentru nivelul RAID 5, folosind patru discuri.
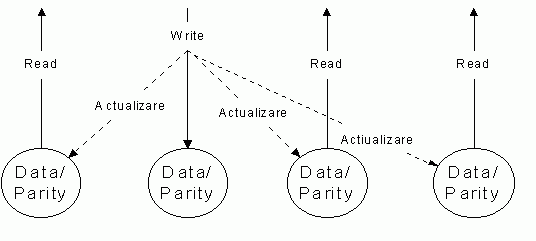
Fig. 8. Operatiile de scriere/citire pentru nivelul RAID 5, folosind patru discuri
C�nd data este scrisa �n matricea RAID 5, informatia de paritate trebuie sa fie reactualizata �n unul din urmatoarele moduri:
1. - informatia de paritate este o operatie XOR a datelor dupa fiecare disc din matrice. Ori de c�te ori data dupa oricare disc este schimbata, celelalte discuri din matrice care memoreaza date sunt citite si aplicate unei operatii XOR pentru a crea noua paritate. Aceasta implica accesarea fiecarui driver din matrice pentru fiecare operatie de scriere;
2. - acest al doilea mod implica gasirea bitilor de date care au fost schimbati de catre operatia de scriere, iar apoi schimbarea bitilor de paritate corespunzatori. Aceasta metoda este acompaniata mai �nt�i de citirea datei vechi pentru a fi rescrisa. Aceasta data este aplicata unui XOR cu noua data care va fi scrisa. Rezultatul este un " bit mask" care are "1" �n pozitia fiecarui bit ce a fost schimbat. Aceasta "bit mask" este apoi aplicata unui XOR cu vechea informatie de paritate care este citita de la driver-ul de paritate din matrice. �n acest fel este posibil sa se determine care biti din vechea paritate au fost schimbati si noua paritate reactualizata este apoi scrisa �napoi pe discul de paritate. Aceasta rezulta �n doar doua citiri, doua scrieri si doua operatii XOR.
Acest dezavantaj al memorarii informatiei de paritate mai t�rziu dec�t o copie a datelor, este datorat timpului �n plus de la durata operatiilor de scriere p�na la regenerarea informatiei de paritate. Acest timp aditional reduce performantele de scriere pentru RAID 5 fata de RAID 1 cu un factor �ntre 3/5 si 1/3. Din acest motiv RAID 5 nu este recomandat pentru aplicatiile de scriere �n care performanta este importanta.
�n urmatoarea figura este ilustrat modul �n care se realizeaza reactualizarea paritatii:
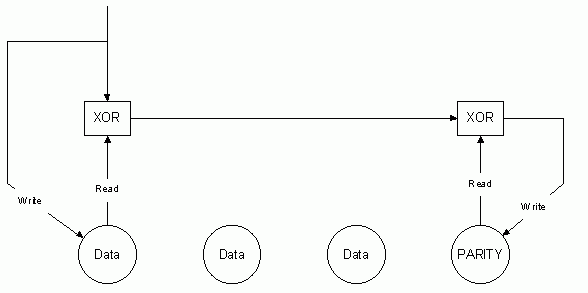
Fig. 9. Reactualizarea paritatii �n timpul scrierilor cu RAID 5
Refacerea datelor pierdute
�n cadrul nivelului RAID 0 c�nd o unitate de hard disc a cazut, �ntreaga matrice de discuri nu mai poate fi folosita.
�n matricea de discuri RAID 1, caderea unui disc are doar un mic impact asupra performantelor, deoarece datele pot fi
citite de la discul oglinda.
�n matricea RAID 5, datele trebuie sa fie reconstruite prin citirea si aplicarea unei functii XOR feliilor de date
corespunzatoare de la discurile ce ram�n �n matrice. Acest proces este �nsa relativ �ncet; cu c�t mai multe discuri
sunt �n matricea RAID , cu at�t operatiile devin mai �ncete. �n figura urmatoare este ilustrat procesul de reconstructie
al datelor pe un sistem cu RAID 5.
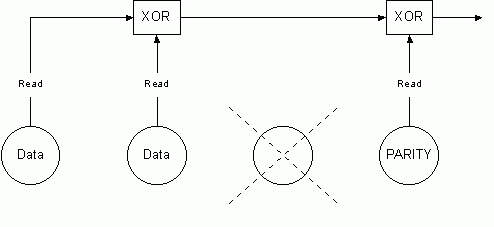
Fig. 10. Procesul de reconstructie al datelor pe un sistem cu RAID 5
Reconstructia unui hard disc deficient
Atunci c�nd un disc defect este �nlocuit �ntr-o matrice RAID 1 sau 5, controlerul SCSI va reconstrui data pierduta pe noul driver. Aceasta operatie de reconstructie are loc �n decursul citirilor si scrierilor normale din matrice. �n cazul matricii RAID 1, reconstructia va avea loc relativ repede, deoarece ea implica doar copierea datei continute �n discul oglinda pe noul disc re�nlocuit.
�n cazul matricii RAID 5, noua data ce urmeaza a fi scrisa pe cel mai nou re�nlocuit disc, trebuie sa fie recreata prin citirea si aplicarea unei functii XOR feliei de date corespunzatoare de la discurile remanente �n matrice. Acest lucru cauzeaza o considerabila degradare a performantei pe durata operatiei de reconstruire, care va dura cu at�t mai mult cu c�t sunt mai multe discuri �n matrice.
Operatii pe un sistem cu RAID 5
1. Operatie normala
Un subsistem de discuri ce opereaza sub mediul RAID 5, memoreaza datele �n felii largi de-a lungul matricii de discuri, folosind o schema de paritate rotativa cu XOR. At�t timp c�t nu a avut loc nici o cadere de discuri vom avea urmatoarea schema:
Fig. 11. Functionare normala
2. Caderea unui disc
Consideram exemplul precedent; presupunem ca una din unitatile de hard disc (de exemplu unitatea 3 ) produce o deficienta. Unitatea de disc defecta este reprezentata �n figura ca nefiind prezenta din punct de vedere logic. �ncep�nd din acest moment p�na c�nd o alta unitate o va �nlocui si datele vor fi reconstruite pe aceasta din urma, accesul la hard discurile subsistemului va fi �ncetinit datorita �ncarcarii pe controlerul SCSI; controllerul acopera datele discurilor pentru accesurile de citire prin executarea de XOR pe feliile corespunzatoare de la unitatile de disc remanente �n sistem.
3. Reconstructia noii unitatii de hard disc
Unitatea de hard disc ce a generat disfunctia este �nlaturata din sistem si apoi �nlocuita cu o noua unitate. Dupa ce vechea unitate a fost �nlocuita, controlerul SCSI de RAID va �ncepe sa reconstruiasca datele ce se gaseau pe discul cazut, pe noua unitate introdusa �n sistem. Pentru fiecare linie de felii din matrice, controlerul executa un SAU EXCLUSIV (XOR) pentru informatiile de date/paritate, de la feliile celorlalte unitati de discuri, iar datele rezultate le scrie pe felia discului nou introdus.
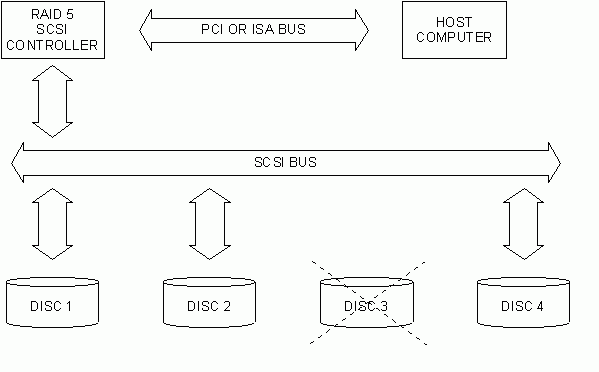
Fig. 12. Matricea RAID 5 dupa caderea unui harddisk
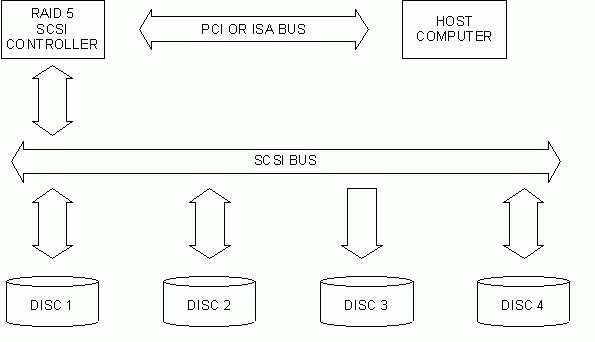
Fig. 13. Reconstructia datelor lipsa pe harddisk-ul nou introdus
Dimensiunea blocului de date
O problema care trebuie rezolvata atunci c�nd se proiecteaza un sistem RAID este aceea de alegere a dimensiunii blocului de date, deoarece majoritatea cererilor adresate matricii de discuri sunt de un singur bloc. Fiecare acces la date de dimensiuni mai mari de un bloc necesita contributia mai multor discuri, deci pentru a �mpiedica posibilitatea unor cereri multiple pentru acelasi disc se va folosi fie reordonarea acceselor la matricea de discuri (cu ajutorul unei stive de comenzi), fie folosirea unor buffere de date mari,depasind 1MB) care stocheaza datele p�na c�nd sunt disponibile si celelalte discuri pentru a se finaliza accesul corect.
Dimensiunea unui bloc de date poate fi un multiplu al dimensiunii unei piste; astfel, �n cazul unor cereri multiple, se vor putea pozitiona cu usurinta capetele discului la �nceputul zonelor respective, determin�nd astfel un timp de cautare si de transfer mult mai redus. Deoarece dimensiunea unei piste este un multiplu al sectorului (512 octeti), pentru un aliniament optim al feliilor de date trebuie sa alegem dimensiunea acestora astfel �nc�t sa reducem timpii de cautare si de pozitionare a capetelor discului.
At�t nivelul RAID 1 c�t si nivelul RAID 5 folosesc "block-striped array" ce �mparte datele �n mai multe blocuri, care apoi sunt stocate pe discuri separate. Avantajul metodei "block-striping" este legat de posibilitatea ca oricare disc sa adreseze independent date de dimensiune mai mica sau egala cu cea a blocului de date.
RAID 1 scrie datele �n cadrul matricii de discuri cu o redundanta "mirror", astfel �nc�t atunci c�nd controllerul scrie un bloc pe un disc, va scrie acelasi bloc si pe discul "mirror".
RAID 5 care foloseste N discuri va scrie blocuri distincte de date pe cele N-1 discuri, iar apoi calculeaza blocul de paritate pe care �l scrie pe cel de-al N-lea disc.
Pentru a putea folosi avantajul matricii "block-striping" controllerul trebuie sa implementeze o coada de comenzi primite de la CPU. Acesta permite servirea unor cereri de I/O concurente, �n timp ce fara aceasta coada s-ar putea servi doar o singura cerere comport�ndu-se ca un singur disc cu informatie redundanta. Atunci c�nd avem un mic procent din cereri ce depasesc dimensiunea blocului de date, pierderea de performanta este mica comparativ cu cazul �n care toate cererile de date sunt mai mari dec�t blocul de date, �n acest caz trebuind accesate doua discuri pentru a efectua un transfer. Aceste lucruri sunt valabile �n ipoteza �n care controllerul acceseaza discurile �n paralel (concurent). �n mod normal asemenea sisteme folosesc tehnici de accesare �n paralel si alte tehnici de management ale acceselor; una dintre aceste tehnici este cea prin care se implementeaza o coada de comenzi �n cadrul unei matricii de discuri cu controller care reordoneaza cererile, introduc�nd �nt�rzierii fiecarei comenzi, �nsa pe ansamblu beneficiile fiind considerabil superioare nivelului costului.
O alta posibilitate este folosirea unui buffer mare (mai mare de 1MB) pentru a stoca datele deja prelucrate p�na c�nd controllerul asteapta disponibilizarea discului dorit �n cadrul transferului. �n acest caz sistemul de operare gazda trebuie sa respecte ordinea de initiere a acceselor de date.
Daca dimensiunea blocului de date este aleasa mai mica dec�t majoritatea cererilor, exista posibilitatea accesarii datelor care nu sunt corect aliniate din punct de vedere al delimitarii blocurilor. Lipsa alinierii �nseamna pentru controller accesarea unei date ce �ncalca granita dintre doua blocuri, deci accesarea de pe doua discuri. Nealinierea, �n cele mai multe din cazuri este consecinta alegerii gresite a dimensiunii blocului de date: doua discuri trebuie sa satisfaca o singura cerere, �n acelasi mod �n care pentru blocuri de 8 KB, o citire de 16 KB implica doua operatii de seek. Pierderile de viteza sunt mai mici �n cazul lipsei alinierii dec�t �n cazul alegerii unui bloc de dimensiune mai mica, deoarece sistemul de fisiere poate fi corectat din punct de vedere al alinierii prin reordonarea cererilor pentru a se asigura ca toate cererile sunt �ndreptate catre adresele de �nceput ale blocurilor.
Algoritmi RAID
Pentru a mari performantele discurilor se impune folosirea unui controller de cache; acesta va realiza anticipat transferurile ce urmeaza a fi facute si de asemenea va satisface cererile actuale �n timp ce magistrala locala a sistemului este ocupata cu transferul �ntre alte dispozitive. Folosirea unui cache destinat calcularii anticipate a citirilor viitoare se numeste "Read Ahead Cache". Memoriile cache sunt de tip asociativ si se bazeaza pe faptul ca o cautare �n memorie dureaza mai putin dec�t un acces la disc.
-
Metodele de cautare a datelor sunt urmatoarele:
- LOOK THROUGH, �n care se parcurge mai �nt�i memoria tampon (cache-ul) si apoi hard discul;
- LOOK ASIDE, �n care se porneste simultan cautarea �n memoria cache si pe hard disc;
- MONITORING, foloseste un controller pentru a lua decizii privind ordinea de cautare.
�n cazul sistemelor RAID, trebuie rezolvata problema mentinerii redundantei matricii de discuri, deoarece �n cazul �ntreruperii accidentale a alimentarii noile blocuri de paritate si de date aflate �n memoria cache nu au fost �nca salvate put�ndu-se astfel pierde; acest lucru are loc datorita algoritmului de �nlocuire a liniilor si datorita faptului ca salvarea datelor �n memoria cache are loc doar �n urma satisfacerii conditiilor de �nlocuire a liniilor. O solutie simpla, �nsa scumpa, este folosirea unei memorii cache non-volatile. Memoria cache poate fi implementata la nivelul controller-ului sau poate fi separata, expandata sau memorie non-volatila. �n cazul implementarii memoriei cache la nivelul controller-ului exista urmatoarele avantaje: se pot procesa rapid datele provenite de la mai multe host-uri cu mecanismele de protectie adiacente; functiile cozii de comenzi, operatiile de seek, transferurile DMA si alte functii de optimizare sunt executate de catre controller, degrev�nd astfel procesorul gazda de aceste operatii, el put�nd executa astfel alte task-uri. Exista trei algoritmi utilizati, fiecare prezent�nd un anumit avantaj:
- algoritmul de �nlocuire aleator (RR-random replacement);
- algoritmul LRU (Least Recently Used);
- algoritmul SLRU(Segmented LRU).
Algoritmul RR - determina numarul liniei care iese din memoria cache folosind un generator de numere pseudoaleatoare. Acest algoritm este usor de implementat, �nsa performantele generale sunt slabe datorita inexistentei unor asocieri �ntre atributele spatiale si temporale ale unei cereri de date.
Algoritmul LRU - este cel mai folosit datorita gradului mare de generalitate pentru solutii diferite; este folosit pentru managementul memoriei virtuale, a sistemelor de fisiere si a operatiilor de I/O. Acest algoritm implementeaza o stiva LRU ce va contine numarul liniei din memoria cache, iar �n v�rful stivei se va afla tot timpul numarul liniei cel mai recent utilizate si �n ordine descrescatoare celelalte linii p�na la ultima care reprezinta coada stivei si care este numarul liniei cel mai putin utilizate. Acest algoritm foloseste principiul determinarii temporale conform caruia o linie utilizata la un moment dat nu va mai fi utilizata �n viitorul apropiat. Dezavantajul acestui algoritm �l reprezinta modul defectuos de predictie al accesarilor viitoare si �nlocuirea neeconomica a liniilor �n acest caz.
Algoritmul Segmented LRU (SLRU) - se implementeaza o memorie cache cu un continut suplimentar �n care se scriu datele ce au fost �nlocuite; memoria cache SLRU este �mpartita �n doua segmente:
- segmentul de proba, care este segmentul principal �n care sunt �nscrise datele;
- segmentul de protectie care reprezinta directorul secundar pentru liniile ce au fost �nlocuite de algoritm.
Liniile �n fiecare segment sunt ordonate de la cea mai recent utilizata la cea mai putin utilizata; �n memorie liniile sunt �n acelasi segment fizic, diferenta fiind data de un bit atasat ce determina segmentul careia apartine. Algoritmul SLRU protejeaza datele ce vor fi accesate de mai multe ori introduc�ndu-le �n segmentul de protectie daca apare un semnal de hit, �nlocuindu-le pe cele cu unica folosinta.
Exemple de implementare a tehnologiilor RAID
Un prim exemplu elocvent de implementare a tehnologiei RAID �l reprezinta subsistemele RAID RM-50FC si DS-50FC de la firma AC&NC. Ele sunt folosite pentru stocari de date, utilizate cu precadere �n retelele LAN, acolo unde sunt necesare capacitati mari de stocare a datelor. Cel mai nou produs, RM-50FC, este un sistem de stocare de date full Fiber Channel ce ofera o �nalta perormanta si cea mai mare siguranta �n stocarea datelor.
Controllerele RAID ale acestui subsistem suporta tehnologiile RAID 0, 1, 3, 4 si 5; are prevazut un disc global de rezerva, posibilitatea de reconstructie automata a datelor precum si 512 MB de memorie cache de date. Fiecare subsistem RM-50FC poate suporta p�na la 110 unitati de disc.

Fig. 14. Subsistem RM-50FC
Capacitatea discurilor poate fi: 18GB (10.000 rpm), 36GB (10.000 rpm) or 73GB (10.000 rpm), put�ndu-se ajunge astfel la o capacitate maxima de 8.03 TB.
-
Specificatii tehnice:
- Arhitectura RAID: CPU AMD K6 300MHz, cu o cale de date de 533 MB/sec, DMA, pe 64 de biti;
- Interfata magistralei de disc: patru Fiber Channel de 100 MB/sec;
- Numarul de unitati de disc pe canal: maxim 55 de unitati;
- Memorie cache: 512 MB;
- Sisteme de operare suportate: Windows NT, Windows 2000 si MSCS (Microsoft Cluster Server), SCO Unix, SunOS/Solaris, IBM AIX, MAC OS, Linux, Novell, OS/2, DOS precum si multe altele;
- Marime, greutate: 48 cm latime, 48 cm lungime, 18 cm �naltime, 19 kg fara unitatile de disc;
Un alt exemplu de implementare a tehnologiei RAID este JetStor II-FC, a carui matrice RAID este bazata pe noile controllere RAID cu cinci canale LVD / FC Ultra2 SCSI 64-bit. Acesta ofera o performanta excelenta datorita folosirii interfetei de disc Ultra2 SCSI, a interfetei Fiber Channel de 100MB/sec si este independent de un sistem de vreun sistem de operare. O performanta mai buna poate aduce un beneficiu performantei sistemului I/O �n general, particulariz�nd pentru tranferurile unor blocuri mari de date.
Fiecare unitate JetStor II-FC RAID poate suporta p�na la opt unitati de disc de 3.5", care pot fi amplasate �n locatii speciale.
Costurile scazute de implementare si depanare sunt asigurate de design-ul cableless oferit de JetStor II-FC, de doua surse de energie redundante, de sase ventilatoare si, bine�nteles, de controlerul RAID. JetStor II-FC este realizat �n doua variante: tower desktop si rackmount .

Fig. 15. JetStor II-FC: tower desktop si rackmount
Capacitatea discurilor poate fi: 9.1GB (7.200 / 10.000 rpm), 18GB (7.200 / 10.000 / 15.000 rpm), 36GB (7.200 / 10.000 rpm), 73GB (10.000 rpm), and 180GB (7.200 rpm). Capacitatea totala este de 1440 GB, folosind discuri cu capacitatea maxima de 180GB.
Controllerele RAID suporta tehologiile RAID 0, 1, 3 si 5; are prevazut un disc global de rezerva, posibilitatea de reconstructie automata a datelor, precum si p�na la 128 MB de memorie cache de date SO-DIMM SDRAM.
- Specificatii tehnice:
- Arhitectura RAID: CPU 66 MHz RISC pe 64 de biti, cu 264 MB/sec, calea de date DMA pe 64 de biti;
- Memoria cache: p�na la 128 MB �ntr-un singur slot de 144 de pini SO-DIMM SDRAM;
- Sisteme de operare suportate: Windows NT, Windows 2000 si MSCS (Microsoft Cluster Server), SCO Unix, SunOS/Solaris, IBM AIX, MAC OS, Linux, Novell, OS/2 precum si multe altele;
- Marime, greutate: 48 cm lungime, 30 cm latime, 22 cm �naltime, 12.2 kg fara unitatile de disc.
RAID 5-3
RAID 5-3 este o varianta hibrida �ntre RAID 0, 1, 3 si 5. Se mai numeste "Parallel Array with Parity, Mirrored". Are doua niveluri. �n nivelul de jos exista o zona de date �n paralel, cu disc de paritate, ca la RAID-3. �n nivelul de sus, RAID-3 este vazut ca disc virtual (RAID-0), la care se aplica "mirroring" (RAID-1). Prezinta performante ridicate la operatiile de scriere/citire, dar fiabilitatea este mai slaba. �n reconstructia datelor se obtin performante asemanatoare cu RAID-5. Are redundanta R = 25%.
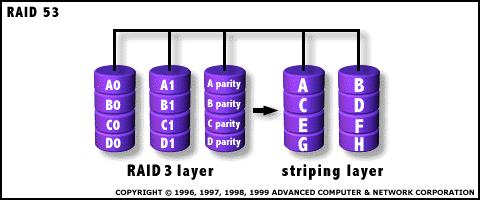
Fig. 16. RAID 5-3 - Rate mari de I/O si transfer performant de date
Avantaje
1. Are aceeasi tolerant� a erorii ca si RAID 3, dar si acelasi control al erorilor.
2. Ratele de transfer foarte mari sunt obtinute datorit� segmentelor de suprafat� RAID 3.
3. Ratele mari de I/O pentru cereri mici sunt obtinute cu ajutorul diviz�rii RAID 0.
4. Este o solutie excelent� pentru site-urile care ar fi mers si cu RAID 3, dar care necesit� un surplus de performant�.
Dezavantaje
1. Foarte costisitor ca implementare.
2. Rotatia tuturor discurilor trebuie s� fie sincronizat�, ceea ce limiteaz� alegerea discurilor.
3. Divizarea octetilor duce la o utilizare proast� a capacit�tii formatate.
Comparatie nivele RAID
Inapoi la Index