Tehnologia
RAID
1. Obiectivul lucrarii
Lucrarea urmareste intelegerea tehnologiei
RAID (Redundant Array of Independent
Disks), a modului de scriere si de citire al datelor si verificarile care
au loc pentru fiecare nivel in parte.
2. Introducere teoretica
Tehnologia RAID (Redundant
Array of Independent/Inexpensive Disks – matrice redundanta de discuri
independente/ieftine) a fost definita pentru prima data de un grup de oameni de
stiinta de la Universitatea Berkeley din California, in 1987. Acestia au
studiat posibilitatea de a utiliza doua sau mai multe hard disk-uri, astfel
incat acestea sa apara sistemului gazda ca fiind un singur dispozitiv.
Pe langa definirea nivelelor RAID initiale de la 1
la 5, oamenii de stiinta au studiat data
striping – distribuirea (partajarea) datelor pe o matrice de discuri
nerendundante. Cunoscuta ca RAID 0, aceasta configuratie nu ofera niciun
mecanism de protectie a datelor, dar permite un flux maxim pentru aplicatiile
care realizeaza transferuri masive de date, cum ar fi productia video digitala.
Datorita evolutiei complexitatii programelor, in
timp au aparut urmatoarele probleme de rezolvat:
·
asigurarea securitatii datelor;
·
marirea vitezei de acces la date.
S-a
trecut la realizarea unor matrice de discuri fizice grupate logic in volume,
care trebuie sa asigure distribuirea datelor, precum si implementarea unei
structuri care sa asigure securitatea datelor prin utilizarea redundantei.
Conceptul RAID implica patru
componente:
·
zonarea datelor;
·
performante ridicate ale timpului de acces;
·
capacitate de stocare marita;
·
redundanta datelor si fiabilitatea.
2.1. Organizarea datelor
Organizarea datelor in cadrul ariilor de discuri presupune doua
componente complementare:
· mecanismul de
redundanta;
· schema de
distributie.
Mecanismul de redundanta specifica tipul,
scopul si localizarea fiecarei informatii redundante din zona de discuri. In
mod curent, se folosesc disk mirroring
(dublarea discului) si informatia de paritate. Acest mecanism permite
sistemului de discuri sa poata fi folosit fara erori si dupa ce un disc fizic
s-a defectat, avand loc reconstructia datelor.
Schema de distributie a datelor defineste algoritmul
de translatie al adresei logice externe (care este vizibila utilizatorului) si
adresele fizice ale discurilor incluse in zonele respective.
Exista doua arhitecturi de baza:
·
adresarea independenta a fiecarui disc (arhitectura
conventionala);
· disk striping (presupune impartirea
discului in parti egale).
Distribuirea datelor presupune maparea adreselor
logice ale volumului de discuri la discurile fizice componente. Abordarea
curenta implica adresarea curenta a fiecarui disc si maparea blocului logic
direct catre blocul de pe fiecare disc. Distribuirea datelor este facuta
“manual” de catre administratorii de sistem, de programele de aplicatii sau de
catre sistemul de operare. In general, administratorul de sistem este
responsabil pentru decizia privind stabilirea locului fiecarei date pe disc.
Arhitectura de disk
striping transforma mai multe spatii de adresare intr-un singur spatiu de
adrese, spatiul unificat folosit de catre procesorul gazda pentru realizarea
transferurilor necesare.
2.2. Redundanta datelor
Mecanismele
de implementare a redundantei datelor sistemului de stocare reduc capacitatea de
stocare, insa asigura protectia datelor in cazul caderii sistemului. Timpul
mediu dintre doua defecte consecutive (MTBF – Mean Time Between Failures) este de circa 500.000 ore; cu toate
acestea timpul mediu de viata al unui volum de discuri neredundant este de
ordinul lunilor, fiind invers proportional cu numarul de discuri care
alcatuiesc sistemul. Daca discurile sunt adresate independent, se poate pierde
1/N din numarul de fisiere sau 1/N din datele fiecarui fisier in cazul
folosirii disk striping-ului. Din
acest motiv, trebuie sa se includa un mecanism de implementare a redundantei
datelor, mecanism care poate asigura protectia in cazul uneia sau a mai multor
caderi ale discurilor. O solutie simpla de protectie este aceea de a folosi
cópii identice; astfel, un bloc de date este scris pe M discuri
distincte, datele considerandu-se pierdute atunci cand originalul si cele M
copii sunt pierdute.
Pentru
protectie se folosesc urmatoarele metode:
· disk mirroring;
· disk duplexing;
· parity;
Metoda disk mirroring realizeaza scrierea
datelor identic pe cele doua discuri distincte. In acest caz, fiecare sistem de
N+1 discuri distincte poate
supravietui caderii a N discuri.
Metoda disk duplexing realizeaza scrierea
datelor tot pe doua discuri, insa canalul de date este distinct pentru fiecare
disc.
Metoda parity
foloseste un disc suplimentar N+1,
care stocheaza datele de paritate ale celorlalte N discuri. Se foloseste unul din cei doi algoritmi de protectie:
codul Hamming de corectie al erorilor (ECC – Error Corection Code) sau operatia logica sau-exclusiv (XOR).
Solutia software este inferioara, in acest
caz procesorul gazda (host-processor) trebuind sa execute si operatiile
de I/O pentru matricea de discuri, reducand astfel performantele sistemului;
aceasta solutie se practica atunci cand se doreste capacitate de stocare mare
si toleranta la defectari.
Solutia hardware este optima, ea folosindu-se atunci cand viteza si
performantele de acces sunt factori critici. Aceasta solutie este mai
costisitoare, ea implicand utilizarea unui controler dedicat comunicatiei
dintre CPU si discuri; acest controler specializat contine un procesor RISC
dedicat implementarii algoritmului RAID, in acest caz unitatea centrala (sau
serverul sistemului, daca se lucreaza in retea) fiind degrevate de operatiile
I/O, mentinandu-si astfel performantele neafectate.
2.3. Nivelele RAID
2.3.1. RAID 0
RAID 0 nu a fost definit de inginerii de la
Berkeley, dar a devenit un termen comun. Este o matrice de discuri
independenta, fara redundanta, care acceseaza datele de pe toate hard
disk-urile la nivel de blocuri de date. Pentru a realiza acest lucru, este
scris/citit primul bloc de date pe/de pe primul hard disk, apoi al doilea bloc
pe/de pe al doilea hard disk s.a.m.d. RAID 0 se adreseaza doar cresterii
fluxului de date si capacitatii de stocare. Datele sunt partajate (data striping) pe mai multe discuri,
fara nicio informatie redundanta.
Nivelul RAID 0 este reprezentat in figura 1.

Fig. 1. RAID 0: Non-redundant striped array – matrice de discuri cu date
distribuite, nerendundanta
La acest nivel nu exista niciun fel de
toleranta la erori. Daca apare un defect la unul din hard disk-uri, intregul
sistem se prabuseste. La fel s-ar fi intamplat si daca datele s-ar fi gasit pe
un singur disc. Avantajul principal al matricei de discuri este transferul mai
rapid de date. Acesta creste cu cresterea numarului de unitati SCSI.
RAID 0 necesita
minimum doua discuri pentru a fi implementat.
·
Scrierea se poate face simultan pe toate
hard disk-urile.
·
Citirea se poate face simultan de pe toate hard
disk-urile
2.3.2.
RAID 1
Aceasta tehnologie realizeaza toleranta la erori
altfel decat RAID 0, 3 sau 5. In RAID 1, cand se face scrierea datelor pe disc,
se face o copie exacta a acestora pe un al doilea disc (mirror disk – disc oglinda), in mod automat si transparent pentru
sistem, aplicatie sau utilizator. Discul oglinda devine astfel o copie exacta a
discului principal.
Interfata cu discurile se poate face cu unul sau
doua controlere. Un singur controler ofera o performanta de citire/scriere
asemanatoare celei a unui singur hard disk. Daca se folosesc doua controlere
(cate unul pentru fiecare hard disk = duplexing),
se reduce riscul de a avea un singur dispozitiv care, in cazul unui defect, ar
duce la caderea ambelor hard disk-uri. De asemenea, duplexing-ul poate imbunatati rata de transfer prin
scrierea/citirea alternativa a datelor pe/de pe cele doua unitati. Comparativ,
in cazul unui singur controler, performanta la scriere este mai redusa, pentru
ca datele trebuie scrise intai pe discul principal si apoi pe discul „oglinda”.
Nivelul RAID 1 este reprezentat in figura 2.

Fig.
2. RAID
1: Mirrored array – matrice de
discuri „oglindite” (dublate).
Intre nivelele RAID, nivelul 1 ofera cea mai mare
disponibilitate a datelor, pentru ca sunt mentinute doua cópii complete. In
plus, performanta la citire poate fi imbunatatita daca controlerul matricei de
discuri permite citirea simultana de pe ambele unitati ale unei perechi.
La scriere, va aparea o usoara scadere in
performanta, comparativ cu scrierea pe un disc obisnuit. O disponibilitate mai
mare poate fi obtinuta daca cele doua discuri ale unei perechi sunt conectate
la magistrale I/O separate. Marele dezavantaj este ca numai jumatate din
capacitatea de stocare este efectiv utila si marirea acesteia se poate face
numai in perechi de discuri.
RAID 1 necesita minimum doua discuri pentru a fi
implementat.
·
Datele se scriu pe o pereche de hard disk-uri.
·
Citirile se pot face simultan de pe toate hard
disk-urile.
2.3.3.
RAID 2
RAID 2 stocheaza datele pe un grup de discuri
impartindu-le in „felii” (chunks), de
obicei de marimea unui sector. Un cod Hamming pentru fiecare ,,felie” este
stocat pe un disc separat, numit check
disk. Codul permite si corectia erorilor.
Datele sunt partajate pe mai multe hard disk-uri,
cateva dintre ele fiind dedicate stocarii informatiilor de detectie si corectie
a erorilor (ECC – Error Checking and Correction) pentru fiecare sector.
Oricum, pentru ca cele mai multe din hard disk-urile actuale au incluse
facilitati ECC la nivel de sector ca facilitate standard, RAID 2 nu ofera
avantaje semnificative comparativ cu arhitectura RAID 3.

Fig.
3.
RAID 3: Parallel array with ECC – matrice
paralela cu corectie ECC.
Nivelul RAID 2 este reprezentat in figura 3.
In prezent, producatorii au renuntat sa mai fabrice
matrice RAID 2.
RAID 2 necesita minimum doua discuri.
· Datele sunt
distribuite pe toate hard disk-urile.
·
Citirea se face de pe toate hard disk-urile.
2.3.4.
RAID 3
In RAID 3, datele sunt distribuite pe mai multe
discuri, la nivel de bit sau octet. Unul din hard disk-urile din matrice
asigura protectia datelor, pastrand octetul de verificare a paritati pentru
fiecare unitate de alocare. La fel ca la RAID 0, discurile sunt accesate
simultan, dar exista in plus hard disk-ul de paritate.
Nivelul RAID 3 este reprezentat in figura 4.

Fig. 4. RAID 3: Parallel array with parity – matrice paralela cu informatii de
paritate.
Datele sunt scrise/citite simultan pe/de pe toate
unitatile, iar bitul de paritate este calculat si comparat cu cel de pe discul
de paritate (la citire), sau scris pe respectivul disc (la operatia de
scriere). Astfel, pentru fiecare octet scris, se calculeaza un bit de paritate
pentru a mentine integritatea datelor. Aceasta permite ca matricea de discuri
si sistemul sa fie 100% functionale si in cazul defectarii unui hard disk din
matrice. In acest caz, se poate continua citirea sau scrierea de pe celelalte
unitati. Bitul de paritate permite refacerea datelor de pe discul defect.
Inlocuirea unitatii defecte se poate face on-line (hot-swapped), dupa care controlerul matricei de discuri
reconstruieste datele pe acesta.
Avantajele RAID 3 fata de nivelele anterioare este
ca procentul ocupat de informatia redundanta (de paritate) din totalul
capacitatii de stocare descreste pe masura ce creste numarul hard disk-urilor.
De asemenea, dispune de cai paralele de transmitere
a datelor, oferind astfel rate de transfer ridicate pentru aplicatiile care
manipuleaza fisiere de dimensiuni mari. Capacitatea matricei poate fi marita cu
cate un hard disk sau in grupuri.
RAID 3 necesita minimum trei discuri pentru a fi
implementat.
·
Scrierea si citirea se face pe/de pe toate hard
disk-urile.
·
Accesul paralel reduce timpul de citire pentru
fisierele mari.
2.3.5.
RAID 4
In RAID 4, informatia de paritate este intretesuta
cu datele utile la nivel de sector dau bloc de date. Ca la RAID 3, un singur
drive este utilizat pentru stocarea datelor redundante, folosind un octet de
paritate pentru fiecare bloc de date. Caile paralele de transfer a datelor si
distributia datelor pe hard disk-urile din matrice la nivel de sector sau bloc
permit efectuarea de operatii independente pe diversele unitati si executarea
in paralel a operatiilor de intrare/iesire.
Nivelul RAID 4 este identic cu RAID 3, cu exceptia
faptului ca se utilizeaza unitati de alocare mai mari, astfel incat
informatiile pot fi citite de pe un hard disk din matrice independent de discul
de paritate. Acest lucru permite suprapunerea in timp a operatiilor de citire.
Nivelul RAID 4 este reprezentat in figura 5.

Fig. 5. RAID 4: Striped
array with parity – matrice de discuri cu datele distribuite, cu paritate.
RAID 4 ofera performante ridicate de citire si
relativ bune de scriere. Aceasta este o solutie de utilitate generala,
aplicabila mai ales acolo unde raportul citiri/scrieri este ridicat. Astfel,
RAID 4 este o alegere buna pentru transferuri de blocuri de date mici, tipice
pentru sistemele de procesare a tranzactiilor.
Performantele la scriere sunt scazute, pentru ca la
fiecare scriere trebuie sa se scrie si bitul de paritate pe hard disk-ul
respectiv. Astfel, hard disk-ul de paritate devine o frana in calea
performantei ridicate cand sunt necesare multe scrieri ale informatiei de
paritate. In acest caz, RAID 5 este o solutie mai buna, deoarece informatia de
paritate este distribuita pe toate discurile disponibile.
RAID 4 aproape ca nu a fost implementat in practica,
pentru ca nu ofera avantaje semnificative fata de RAID 5.
RAID 4 necesita minimum trei discuri pentru a fi
implementat.
·
Fiecare operatie de scriere trebuie sa actualizeze
drive-ul de paritate.
·
Citirea se poate face simultan de pe toate hard
disk-urile.
2.3.6.
RAID 5
RAID 5 combina fluxul masiv de date oferit de RAID 1
– prin partajarea datelor la nivel de bloc – cu mecanismul de refacere a
datelor prin intermediul informatiilor de paritate. Acest nivel de toleranta la
erori integreaza informatia de paritate la nivel de sector cu partajarea
datelor si informatiilor de paritate pe toate hard disk-urile, fara a avea deci
o unitate dedicata stocarii informatiilor de paritate. Aceasta permite multiple
operatii de intrare/iesire concurente, ceea ce conduce la un flux de date
imbunatatit, cu mentinerea integritatii datelor. Un disc anume din matrice este
accesat doar atunci cand trebuie scrise/citite date sau informatii de paritate
pe/de pe acesta.
Nivelul RAID 5 este reprezentat in figura 6.

Fig.
6.
RAID 5: Striped array with distributed
parity – matrice distribuita cu paritate distribuita.
In RAID 5, discurile pot raspunde independent
cererilor de acces, ceea ce ofera o performanta sporita la citire intr-un mediu
cu solicitari intense de acces. Datorita informatiilor de paritate, o matrice
RAID 5 poate supravietui caderii unui disc fara pierderea datelor sau
intreruperea accesului la acestea.
Punctul forte al acestei tehnologii este manipularea
unui numar mare de fisiere mici. Rata de transfer este ridicata, pentru ca nu
mai exista strangularea de la RAID 4 datorata drive-ului de paritate. Desi RAID
5 este mai eficient din punct de vedere al costurilor, pentru ca nu mai este
necesar un drive separat pentru paritate, performanta la scriere are de
suferit. Fiecare operatie de scriere necesita 4 accese independente la disc.
Intai, datele vechi si informatia de paritate este citita de pe discuri
separate. Apoi este calculata noua paritate. In fine, noile date si informatiile
de paritate sunt scrise pe discuri separate.
Multi producatori de sisteme RAID utilizeaza caching-ul
pentru a compensa performantele slabe la scriere. In acest caz, este important
ca acesta sa fie sustinut de un sistem UPS (Uninterruptible
Power Supply).
In aplicatiile grafice, dezavantajul RAID 5 fata de
RAID 3 este slaba performanta la scriere datorata informatiilor de paritate
distribuite, astfel incat RAID 5 este de obicei intalnit in aplicatii cu numar
mare de operatii de citire/scriere scurte. Utilizarea maxima a capacitatii se
obtine atunci matricea are mai putin de 7 discuri. La un numar mai mare,
aceasta este asemanatoare nivelului RAID 3.
RAID 5 necesita minimum trei discuri pentru a fi
implementat.
·
Scrierea necesita actualizarea paritatii.
·
Citirile se pot face simultan de pe toate hard
disk-urile.
2.3.6.1. Reactualizarea paritatii
Cand data este scrisa in matricea RAID 5, informatia
de paritate trebuie sa fie reactualizata in unul din urmatoarele moduri (vezi
figura 7a, 7b):
1. In primul mod, informatia de paritate este o
operatie XOR a datelor de pe fiecare disc din matrice. Ori de cate ori data de
pe oricare disc este schimbata, celelalte discuri din matrice care memoreaza
date sunt citite si li se aplica o operatie XOR pentru a crea noua paritate.
Aceasta implica accesarea fiecarui drive din matrice pentru fiecare operatie de
scriere.

Fig.
7.a.
Reactualizarea paritatii in timpul scrierilor cu RAID 5 (modul 1).
2. Al doilea mod implica gasirea bitilor de date care
au fost schimbati de catre operatia de scriere, iar apoi schimbarea bitilor de
paritate corespunzatori. Aceasta metoda este acompaniata mai intai de citirea
datei vechi pentru a fi rescrisa. Aceasta data este aplicata unui XOR cu noua
data care va fi scrisa. Rezultatul este o masca de bit (bit mask), care are 1 in pozitia fiecarui bit care a fost schimbat.
Aceasta masca de bit este apoi aplicata unui XOR cu vechea informatie de
paritate care este citita de la drive-ul de paritate din matrice. In acest fel,
este posibil sa se determine care biti din vechea paritate au fost schimbati,
iar noua paritate reactualizata este apoi scrisa inapoi pe discul de paritate.
Aceasta rezulta in doar doua citiri, doua scrieri si doua operatii XOR.

Fig. 7.b. Reactualizarea paritatii in timpul
scrierilor cu RAID 5 (modul 2).
Acest dezavantaj al memorarii informatiei de
paritate mai tarziu decat copierea datelor este datorat timpului suplimentar de
la durata operatiilor de scriere pana la regenerarea informatiei de paritate.
Acest timp aditional reduce performantele de scriere
pentru RAID 5 fata de RAID 1 cu un factor cuprins intre 3/5 si 1/3. Din acest
motiv, nivelul RAID 5 nu este recomandat pentru aplicatiile de scriere in care
performanta este importanta.
2.3.6.2. Refacerea datelor
In cazul caderii unui disc, operatia de refacere a
datelor consta in folosirea discurilor ramase (discul de paritate si discurile
de date), datele refacandu-se cu aceeasi suma de paritate folosita la constructia
discului de paritate (vezi figura 8).

Fig.
8. Procesul
de reconstructie al datelor pe un sistem cu RAID 5.
In cadrul nivelului RAID 5, data este impartita de-a
lungul tuturor discurilor din matrice, folosind felii largi, cu cate o felie pe
„linie”, continand datele de paritate. Alocarea acestei felii de paritate este
rotita printre toate discurile din matrice, astfel incat feliile succesive de
paritate sunt intotdeauna scrise pe cate un disc diferit. In eventualitatea „caderii”
unuia din ele (drive failure),
continutul fiecarei felii lipsa poate fi reconstruit din data de paritate
pentru acea „linie”, astfel nepierzandu-se niciun fel de date. Caderea intregii
matrice reclama caderea simultana a doua drive-uri – un eveniment foarte
improbabil.
Atunci cand un disc defect este inlocuit intr-o
matrice RAID 1 sau 5, controlerul SCSI va reconstrui data pierduta pe noul
drive. Aceasta operatie de reconstructie are loc in decursul citirilor si
scrierilor normale din matrice.
In cazul matricei RAID 1, reconstructia va avea loc
relativ repede, deoarece ea implica doar copierea datei continute in discul
oglinda pe noul disc reinlocuit. In cazul matricei RAID 5, noua data care
urmeaza a fi scrisa pe cel mai nou reinlocuit disc trebuie sa fie recreata prin
citirea si aplicarea unei functii XOR feliei de date corespunzatoare de la
discurile remanente in matrice. Acest lucru cauzeaza o degradare considerabila
a performantei pe durata operatiei de reconstruire, care va dura cu atat mai
mult cu cat sunt mai multe discuri in matrice.
2.3.7.
RAID 6
RAID 6 poate fi imaginat ca fiind „RAID5, dar
ceva mai mult”. Se bazeaza pe aceeasi arhitectura ca RAID5, dar cu un grup de benzi
de paritate suplimentara (dubla). Scopul acestei duplicarii este de a
imbunatati toleranta la defecte. RAID 6 se poate ocupa de defectarea a doua
discuri din arie, in timp ce alte configuratii RAID nu pot sa se ocupe decat de
un singur disc.
Din punct de vedere al performantei, RAID 6
este, in general, mai slab decat RAID5 in termeni de scriere, datorita
adaugarii unui numar si mai mare de calcule de paritate, dar poate fi mai rapid
in termeni de citire, datorita imprastierii datelor peste inca un hard disk.

Fig.
9.
RAID 6: Striped array with two
independent distributed parity schemes – matrice distribuita cu doua scheme
independente de paritate distribuita.
Nivelul RAID 6 este reprezentat in figura 9.
La fel ca la RAID 4 si RAID 5, performanta poate
fi ajustata experimentand diferite marimi ale fasiilor.
RAID 6 necesita minimum patru discuri pentru
a fi implementat.
·
Scrierea necesita actualizarea paritatii.
·
Citirile se pot face simultan de pe toate hard
disk-urile.
2.3.8.
RAID 7
Spre deosebire de celelalte nivele RAID, RAID
7 nu este un standard; este o marca inregistrata a firmei Storaqe Computer
Corporation, folosit pentru a descrie designul lor propriu de RAID. RAID 7
se bazeaza pe conceptele folosite la nivelele RAID 3 si RAID 4, dar mult imbunatatite
in mediul limitarilor acelor nivele. O particularitate a acestui nivel este
includerea unui cache aranjat in nivele multiple si un procesor real-time
specializat, care se ocupa cu sincronizarea ariei. Suportul hardware, in
special cache-ul, permite ariei sa se ocupe cu mai multe operatii simultan,
aceasta imbunatatind performanta si toleranta la defectari. In particular, RAID
7 ofera o performanta imbunatatita la citire si la scriere fata de RAID 3 si
RAID 4, deoarece dependenta de discul de paritate dedicat este mult redusa prin
adaugarea hardware-ului. Desigur ca performanta crescuta a lui RAID 7 se face
simtita in costul crescut al acestuia. RAID 7 este o solutie scumpa, fabricata
si promovata de o singura companie.
Nivelul RAID 7 este reprezentat in figura 10.

Fig.
10.
RAID 7:
Asynchronous, cached striping with dedicated
parity
– cache asincron distribuit cu paritate dedicata.
2.4. Nivele RAID hibride
Pentru crearea de nivele etajate de RAID, un nivel
poate fi combinat cu alt nivel, dar cel mai uzual sunt utilizate nivelele 0 si
1. Orice controler hardware (chiar si cele ATA paralel sau serial, foarte
accesibile azi, incluse chiar pe placa de baza) suporta RAID 0, RAID 1 si RAID
0+1, mai rar RAID 10, in functie de implementare.
2.4.1.
RAID 0+1
RAID 0+1 este implementat ca o suprafata
oglindita, ale carei segmente sunt suprafete RAID 0. RAID 0+1 are aceeasi
toleranta la erori ca RAID 5 si acelasi control al tolerantelor la erori ca
oglindirea simpla. Ratele mari I/O se obtin datorita multiplelor segmente
divizate.
Nivelul RAID 0+1 este reprezentat in figura
11.

Fig.
11.
RAID 0+1: Striping and mirroring
combination without parity – combinatie de distribuire si oglindire, fara
paritate.
RAID 0+1 nu trebuie confundat cu RAID 10.
Defectarea unui singur drive va duce la transformarea matricei intr-o matrice
RAID 0. RAID 0+1 ofera o scalabilitate foarte limitata la un pret foarte mare.
Este o solutie ideala pentru site-uri care necesita o performanta ridicata, dar
nu vizeaza o fiabilitate maxima.
RAID 0+1 necesita minimum patru discuri
pentru a fi implementat.
2.4.2.
RAID 10
Este
implementat ca o matrice distribuita, ale carei segmente sunt matrice RAID 1.
RAID 10 are aceeasi toleranta la erori ca RAID 1. Ratele de transfer mai bune
sunt obtinute datorita distribuirii segmentelor RAID 1. In anumite
circumstante, RAID 10 poate rezista la defectari multiple simultane ale
discurilor. Este o solutie foarte buna pentru sisteme care necesita RAID 1, deoarece
aduce un plus de performanta fata de acesta.
RAID 10 este foarte costisitor si are un
nivel ridicat de control. Poate fi utilizat in aplicatii cu servere de baze de
date, care necesita o performanta buna si toleranta la erori.
RAID 10 necesita minimum patru discuri pentru a putea fi implementat.
Nivelul RAID 10 este reprezentat in figura
12.

Fig.
12.
RAID 10: Mirroring and striping
combination without parity – combinatie de oglindire si distribuire, fara
paritate.
2.4.3.
RAID 53
RAID 53 ar trebui numit,
de fapt, „RAID 03”, deoarece este implementat ca o matrice distribuita ale
carei segmente sunt matrice RAID 3. RAID 53 are aceeasi toleranta la defecte ca
RAID 3 si acelasi nivel de control.
Datorita segmentelor RAID 3, se obtin rate
mari de transfer, iar datorita distribuirii RAID 0 se obtin rate de transfer si
mai bune pentru operatii de scriere/citire scurte. Este folositor pentru
sistemele care folosesc RAID 3 si necesita un plus de performanta.

Fig.
13.
RAID 53: High I/O rates and data
transfer performance – transferuri I/O la rate marite si performanta la
transferul datelor.
Este foarte scump de
implementat. Toate acele discurilor trebuie sincronizate, ceea ce limiteaza
alegerea discului.
RAID 53 necesita minimum cinci discuri pentru
implementare.
2.5.
Fiabilitatea nivelelor RAID
MTTR (Mean Time To
Replace) este timpul cat matricea este defecta. Acesta este calculat facand
suma intre doi termeni. Primul este H, timpul pana cand tehnicianul
observa ca un disc s-a defectat si il inlocuieste. H este aproximativ 0
daca se foloseste un disc de rezerva. Al doilea termen este timpul necesar
refacerii datelor alterate. Intr-un sistem optim in care controlerul poate tine
ritmul cu rata de transfer a discurilor si operatia XOR este facuta intr-o
singura rotatie, refacerea datelor poate fi calculata ca timpul necesar pentru
citirea discurilor bune, operatia XOR/rotatie si scrierea datelor pe discul
inlocuit. Astfel, considerand C ca fiind capacitatea si M fiind
rata de transfer, MTTR este calculat cu relatia:
 . (1)
. (1)
Fiabilitatea unei matrice este legata de fiabilitatea discurilor si de
numarul de defectiuni ale discurilor care poate fi tolerat inainte ca matricea
sa devina inaccesibila. Fiabilitatea discurilor este caracterizata de timpul
mediu dintre defectiuni, MTBF (Mean
Time Before Failure).
Fiabilitatea unei matrice neredundante ca RAID 0 este egala
cu raportul dintre etalonul MTBF si numarul de discuri N. Aceasta
este cunoscuta si sub numele de MTTDL_DF (Mean Time To Data Loss due to Disk Failure – timpul mediu pana la
pierderea datelor datorata defectiunii discului):
 . (2)
. (2)
Deoarece matricea RAID 5
poate tolera defectiunea unui singur disc, fiabilitatea discurilor ramase se
poate calcula cu relatia:
 . (3)
. (3)
Combinand ecuatiile (2) si
(3) si luand in considerare timpul de reconstruire al unui disc, se obtine:
 . (4)
. (4)
Fiabilitatea pentru matricea RAID 6 se obtine
in mod asemanator:
 . (5)
. (5)
Se considera ca probabilitatea defectarii al unui al doilea disc dupa
primul este mult mai mare, datorita problemelor hardware aparute. Aceasta este
cunoscuta sub numele de defectiune corelata a discului.
Se presupune ca etalonul MTBF al celui de-al doilea disc este o
zecime din etalonul MTBF al primului disc. Astfel, etalonul MTBF
al celui de-al treilea disc este o sutime din etalonul MTBF al primul
disc etc.
Luand in considerare defectarile corelate ale discurilor, se obtin
urmatoarele relatii:
 , (6)
, (6)
 . (7)
. (7)
Un
al treilea factor pentru etalonul MTTDL este esecul citirii unuia sau al
mai multor blocuri de pe discurile bune ramase in timpul reconstruiri datelor
discului defectat. Sansa ca aceasta sa se intample este proportionala cu rata
de eroare a bitilor BER (Bit Error
Rate) sau cu numarul mediu de biti care trebuie cititi pentru a avea un bit
eronat. Daca dimensiunea unui sector este de 512 octeti, numarul de sectoare
care trebuie citite pentru a avea in medie un sector defect se poate calcula cu
relatia:
 . (8)
. (8)
Presupunand ca erorile sunt aleatoare, probabilitatea p
de succes a citirii tuturor sectoarelor unui disc se calculeaza cu relatia:
 . (9)
. (9)
Atunci etalonul MTTDL corespunzator unei defectiuni a
discului in RAID 5 si unei erori de bit in timpul refacerii discului se
calculeaza cu relatia:
 . (10)
. (10)
In cazul RAID 6, corespunzator defectarii a doua discuri si erorii de
bit in timpul refacerii discului, acelasi etalon se calculeaza cu relatia:
 . (11)
. (11)
In final, etalonul MTTDL corespunzator fie unei caderi de disc,
fie unei erori de bit este media armonica intre MTTDL_DF si MTTDL_BER:
 . (12)
. (12)
Etalonul MTTDL poate fi folosit la compararea fiabilitatii
diferitelor matrice cu tipuri diferite de discuri, numar diferit de discuri si
nivele diferite de RAID.
In concluzie, este important sa se ia in
seama faptul ca fiabilitatea sistemului nu depinde numai de fiabilitatea
discurilor din sistem. In multe cazuri, sistemul de operare este cel care
cauzeaza pierderi de date. De asemenea, fiabilitatea depinde de etalonul MTBF
al altor componente, cum ar fi ventilatoarele sau sursele de curent, care, daca
nu sunt inlocuite prompt, pot contribui la o cadere mai deasa a sistemului
decat discurile.
3. Descrierea aplicatiei
Aplicatia RAID ofera
posibilitatea vizualizarii nivelelor RAID, calculul eficientei si fiabilitatii
acestora, precum si intelegerea modului de protectie a datelor.
Din meniul principal, se poate alege nivelul
RAID si se poate calcula eficienta, pe baza numarului total de discuri
disponibile, parametru introdus de utilizator.

Fig.
14.
Meniul principal al aplicatiei RAID.
Nivelul RAID poate fi ales si un segment al
unei matrice hibride, la care exista de asemenea posibilitatea de a o vizualiza
si de a-i calcula eficienta, dupa cum se poate observa in figura 14.
Pentru nivelele RAID 5 si 6, exista optiunea
de a calcula fiabilitatea matricei si timpul mediu in care se pot pierde date
dupa defectarea unuia sau mai multor discuri din sistem, dupa defectarea
sistemului, sau dupa erori de bit la citire. La alegerea optiunii de a calcula
fiabilitatea, apare o noua fereastra, in care se pot alege parametrii MTTF,
MTTR, numarul de discuri din sistem, probabilitatea de citire a tuturor
sectoarelor unui disc si caracteristicile defectiunii, iar dupa procesarea
parametrilor de intrare mentionati se obtin parametrii de iesire MTBF si
MTTLD, dupa cum se poate observa in figura 15.

Fig.
15.
Fereastra Fiabilitate.
Pentru matricele RAID 2 si RAID 5, se poate alege optiunea de
Scriere/Refacere date, la alegerea careia apare o noua fereastra. La RAID 2, se
observa modul de detectie al erorii folosind codul Hamming corector de o
eroare, dupa cum se poate observa in figura 16.
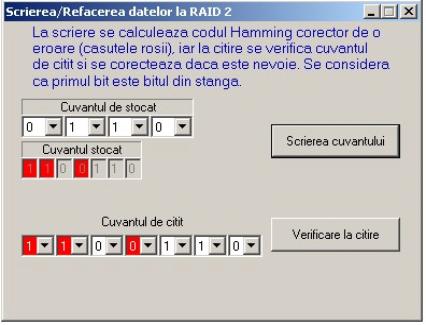
Fig.
16.
Scrierea/Refacerea datelor la RAID 2.
Pentru matricea RAID 5, se explica modul de calcul al paritatii si modul de rescriere al datelor in cazul defectarii unui disc, dupa cum se poate observa in figura 17.

Fig.
17.
Scrierea/Refacerea datelor la RAID 5.
4.
Desfasurarea lucrarii
1.
Se verifica daca este instalat pe calculator
programul RAID. Daca aplicatia nu este instalata, atunci se va instala din
Setup. Se va lansa in executie aplicatia. (Calea default este: C:\Program
Files\UPB\NivRAID\).
2.
Se calculeaza eficienta fiecarui nivel RAID pentru 4
valori distincte ale numarului de discuri. Se noteaza datele intr-un tabel.
3.
Se compara fiabilitatea nivelelor RAID 5 si RAID 6
pentru aceleasi date de intrare de la punctul 2. Se observa si se noteaza
dependenta fiabilitatii fata de numarul de discuri.
4.
Se observa modul de control al erorilor pentru
nivelele RAID 2 si 5.
4.1.
Se calculeaza bitii codului Hamming corector de o
eroare in cazul RAID 2. Se observa ce se intampla la introducerea unui bit
eronat, apoi la introducerea a doi biti eronati.
4.2.
Pentru RAID 5, se calculeaza pe hartie paritatea cu
functia XOR intre 3 siruri de biti alese, apoi se reconstruieste unul din
acestea folosind bitii de paritate.
5.
Intrebari
1.
Care este diferenta intre nivelele RAID 4 si RAID 5?
Dar intre RAID 5 si RAID 6?
2.
De ce nu se mai foloseste nivelul RAID 2?
3.
Cum se calculeaza bitii de control cu codul Hamming
si cum se poate detecta bitul introdus gresit?
4.
Care nivel RAID are o mai buna toleranta la defecte?
5.
Care dintre nivelele RAID 0+1 si 10 este mai bun din
punct de vedere al performantei? Care dintre acestea prezinta o toleranta mai
buna la defecte?
6.
Cum se actualizeaza datele de paritate pentru sistem
RAID 5?
7.
Cum se refac datele pierdute de pe un disc dintr-o
matrice RAID 5?
8.
Care este timpul mediu de pierdere a datelor pentru
matricea RAID 5, stiind ca fiabilitatea unui disc este de 100.000 ore?
9.
Dar fiabilitatea matricei RAID 6 in acelasi caz?
10.
Cum influenteaza probabilitatea erorii de bit durata
in care se pot pierde date?